
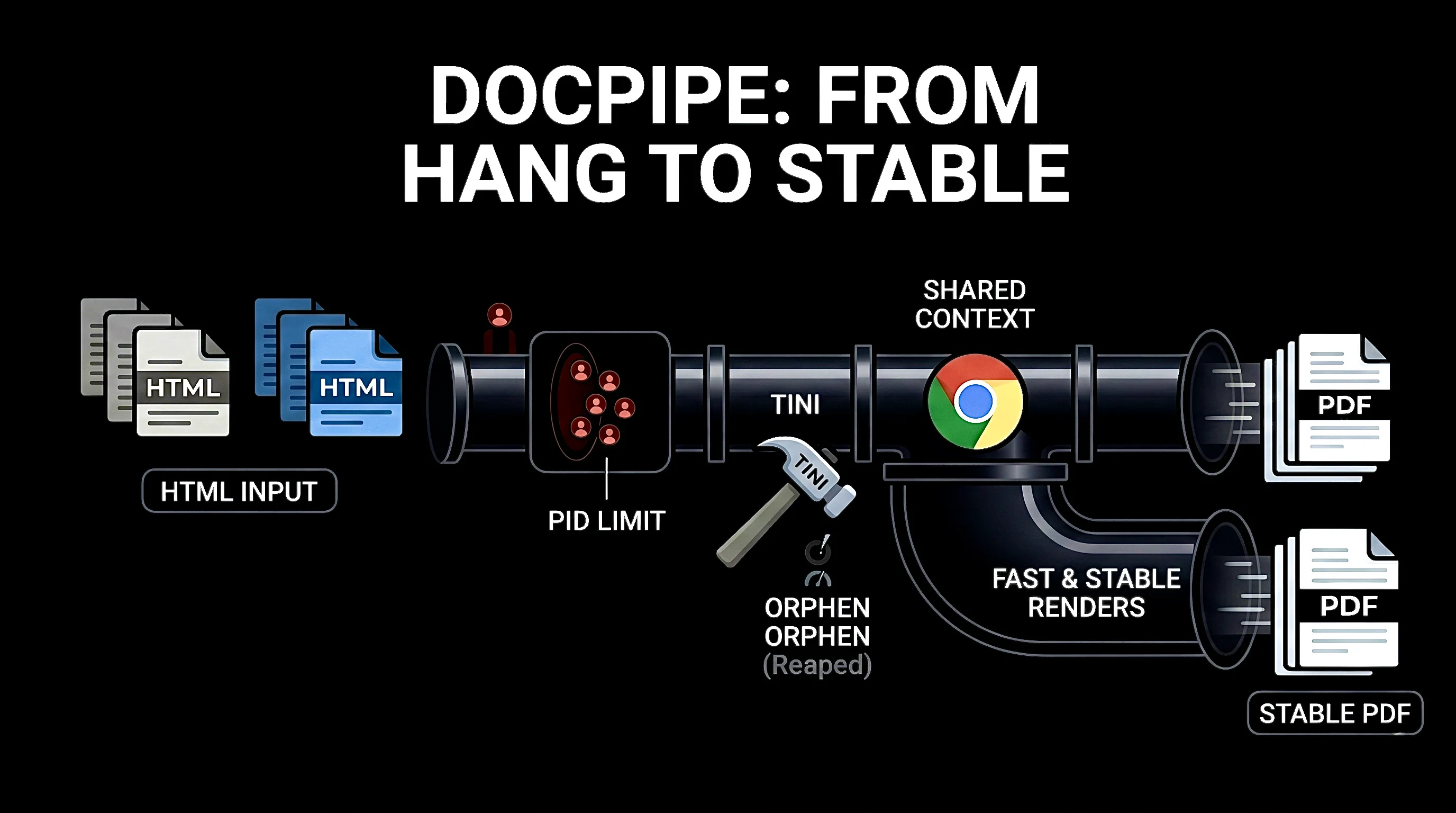
I run a small service called DocPipe. It does one thing: take HTML, return a PDF. The CASCK job portal uses it to generate admit cards — a couple of thousand per hour during exam season, near-zero the rest of the time.
For a year, the v1 implementation was fine. Sixty lines of Go, one HTTP handler, chromedp to drive a headless Chromium. It worked. Then one Tuesday in April it stopped working, and stayed stopped, and the only way back was a container restart.
This is what I learned debugging it, what I rebuilt, and three real bugs I hit while rebuilding that I want to remember.
What v1 looked like
The whole renderer was this, roughly:
func generatePDF(w http.ResponseWriter, r *http.Request) {
var input HTMLInput
json.NewDecoder(r.Body).Decode(&input)
htmlBytes, _ := base64.StdEncoding.DecodeString(input.Base64HTML)
htmlContent := string(htmlBytes)
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
ctx, cancel = context.WithTimeout(ctx, 30*time.Second)
defer cancel()
var pdfBuffer []byte
chromedp.Run(ctx,
chromedp.Navigate("about:blank"),
// assign the decoded HTML into the page body via Evaluate
// (this is wrong; we'll come back to it)
injectHTMLIntoBody(htmlContent),
chromedp.Sleep(10*time.Second),
chromedp.ActionFunc(func(ctx context.Context) error {
buf, _, err := page.PrintToPDF().
WithPrintBackground(true).
WithPaperWidth(8.27).
WithPaperHeight(11.69).
Do(ctx)
pdfBuffer = buf
return err
}),
)
w.Header().Set("Content-Type", "application/pdf")
w.Write(pdfBuffer)
}The injectHTMLIntoBody step mutated document.body directly via Evaluate — which discards everything in <head>: doctype, stylesheets, web fonts. We'll come back to that. But the structural problem, the one that makes it eventually hang, is that every request spawns a fresh Chromium process.
Here's the actual failure mode, in order:
- Request arrives.
chromedp.NewContext(context.Background())spawns a Chromium process and its grandchildren (renderer, GPU, zygote, crashpad).- We render, write the PDF, and
cancel()returns. - The Chromium process exits, but its grandchildren do not get reaped immediately. They become orphans.
- The Go binary is PID 1 in the container. PID 1 has a special responsibility: reaping orphaned children. The Go runtime doesn't do this.
- After tens of thousands of requests, the kernel runs out of process IDs in the container's namespace,
fork()starts failing, and the nextchromedp.NewContextblocks forever waiting on a Chromium that will never start.
I knew about the PID 1 thing — there are blog posts about it going back to 2016 — but I'd convinced myself my service didn't need it because the parent process exits cleanly. It doesn't.
The fix isn't one thing
If you read the literature on this you'll find three independent fixes, each presented as if it alone solves the problem:
- "Use
tinias PID 1." - "Reuse a single browser process via a shared allocator."
- "Don't sleep — wait on a load event."
The annoying truth is that you need all three, and missing any one of them keeps the bug latent.
tini alone reaps grandchildren but you're still paying full Chromium startup cost per request, which limits sustained throughput. A shared allocator alone reduces the number of processes but doesn't reap the ones that do die. Switching from Sleep(10s) to event-based waiting alone just makes the failure happen faster.
So the v2 rebuild had three load-bearing changes:
- One long-lived
chromedp.ExecAllocatorfor the lifetime of the process. Per-request tabs derive from a shared parent context. tinias PID 1 in the container.- Event-based waits —
Page.loadEventFired, optionally with a 500ms network-idle debounce — instead ofSleep.
And then while implementing those three fixes, I hit three more bugs.
Bug one: the chromedp parent-context lifetime gotcha
The pattern I started with was canonical:
allocCtx, allocCancel := chromedp.NewExecAllocator(ctx, opts...)
parentCtx, parentCancel := chromedp.NewContext(allocCtx)
// Warm the browser
probeCtx, cancelProbe := context.WithTimeout(parentCtx, 20*time.Second)
defer cancelProbe()
if err := chromedp.Run(probeCtx, chromedp.Navigate("about:blank")); err != nil {
return err
}
// Now ready for per-request tabs
b.parentCtx = parentCtxI built the service. I started it in Docker. The browser launch succeeded. The first render came in, and failed in 1.7ms with context canceled.
I spent the better part of an hour adding logs. The supervisor probe was passing, then failing, then succeeding again. The parent context's Err() was non-nil within milliseconds of spawn() returning. But nothing was calling parentCancel(). What was canceling it?
The chromedp source. Specifically, this line of behavior that isn't called out in the package docs:
The browser is created lazily on the first
Run. The browser process's lifetime is bound to the context passed to that firstRun.
probeCtx was a child of parentCtx via context.WithTimeout. When I called chromedp.Run(probeCtx, ...), the browser process was attached to probeCtx, not parentCtx. When my deferred cancelProbe() fired at the end of spawn(), it canceled probeCtx — and took the browser with it. The parentCtx was just a wrapper that pointed at a dead browser.
The fix: never pass a child of parentCtx to the first Run. Bound the launch a different way:
launchErr := make(chan error, 1)
go func() {
launchErr <- chromedp.Run(parentCtx, chromedp.Navigate("about:blank"))
}()
select {
case err := <-launchErr:
if err != nil {
return err
}
case <-time.After(20 * time.Second):
return errors.New("browser launch timed out after 20s")
}Now the browser is attached to parentCtx directly. The timeout-via-select bounds the launch without ever giving the cancellation gun to a child context.
The thing that hurts about this bug is that the canonical pattern works for one-shot scripts (NewContext → Run → cancel) because the cancel that kills the browser is intentional. It only breaks when you try to keep the browser alive across multiple Run calls and want a timeout on the launch.
Bug two: a load event that fires while you're not looking
With the browser alive, the next request came in. It hung for the full timeout. Then failed.
The wait strategy was supposed to be "load": fire when Page.loadEventFired arrives. The implementation was:
// inside runRender
chromedp.Run(ctx,
chromedp.Navigate("about:blank"),
setDocumentContentAction(html),
waitForLoad(opts.WaitTimeout),
printPDFAction(opts, &pdf),
)
func waitForLoad(timeout time.Duration) chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
loaded := make(chan struct{})
chromedp.ListenTarget(ctx, func(ev any) {
if _, ok := ev.(*page.EventLoadEventFired); ok {
close(loaded)
}
})
select {
case <-loaded:
return nil
case <-time.After(timeout):
return fmt.Errorf("page load timeout")
}
})
}The actions in chromedp.Run execute sequentially. So setDocumentContent runs, then waitForLoad runs, then printPDF runs. Looks fine.
It isn't fine. Page.setDocumentContent fires loadEventFired synchronously inside the call. By the time the next action installs its listener, the event has already passed. The listener will wait forever — or until our timeout fires.
I worked this out by reading chromedp event listener semantics very carefully and matching them against CDP's Page domain docs. The fix is to install the listener before the action that triggers it. Since chromedp.Run runs actions sequentially, you can't do that across two separate actions — you have to bundle them inside one ActionFunc:
func renderWithWait(html string, opts Options, out *[]byte) chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
// 1. Install the listener BEFORE the action that fires the event.
ready, cleanup := startWait(ctx, opts)
defer cleanup()
// 2. Load HTML — this synchronously fires loadEventFired.
if err := loadHTML(ctx, html); err != nil {
return err
}
// 3. Wait for the listener to signal.
select {
case err := <-ready:
if err != nil { return err }
case <-ctx.Done():
return ctx.Err()
}
// 4. Print.
return printPDF(ctx, opts, out)
})
}The first time I ran this, the render completed in 120ms. The first render had been waiting 3 seconds to time out on a load event that fired 2.999 seconds before the listener attached.
Three lessons compressed into that bug:
chromedp.Runruns actions one at a time. Listeners attached in action N can't catch events fired in action N-1.Page.setDocumentContentis not asynchronous like a real navigation. It's an in-frame mutation that fires load events synchronously.- If your event-driven wait sometimes times out and sometimes returns instantly, you're racing. Test under load before declaring victory.
This was also the moment I went back and fixed v1's other mistake: that injectHTMLIntoBody step from earlier was assigning HTML directly into the body element, which silently discards the whole <head> — doctype, stylesheets, web fonts, the lot. The fix is to call CDP's Page.setDocumentContent against the root frame ID, which replaces the entire document. v1 had been producing cosmetically wrong PDFs the whole time and no-one had noticed because the admit-card template inlined its CSS.
Bug three: Alpine's broken Chromium
With the renderer working in local tests against my system's Chromium, I built the production Docker image. The base I'd planned to use was Alpine 3.20 with the chromium package. Multi-stage build, tini as PID 1, non-root user — by the book.
The container started. The first render returned 500 instantly. Container logs:
chrome_crashpad_handler: --database is required
Try 'chrome_crashpad_handler --help' for more information.chrome_crashpad_handler is the out-of-process crash reporter that ships with Chromium. In Alpine 3.20, the chromium package (version 131) is built such that this subprocess is launched unconditionally — and when launched without --database, it aborts immediately, taking the parent Chromium with it.
I tried every flag I could think of:
--disable-crash-reporter— no effect--no-crash-upload— no effect--disable-features=Crashpad— no effect--disable-breakpad— no effect--noerrdialogs— no effect--user-data-dir=/tmp/c(give crashpad a writable directory) — no effect--single-process(skip the subprocess fork entirely) — no effect
Every invocation died the same way. I went looking at the actual chromium-launcher.sh wrapper, the chromium config files, the binary itself — nothing pointed at a flag that would disable the crashpad subprocess. It's an Alpine packaging bug.
The two fixes I considered:
- Downgrade to Alpine 3.19. Ships Chromium 121, which doesn't have the bug.
- Switch base image to
chromedp/headless-shell— a curated Debian-based image the chromedp project maintains specifically for running headless Chromium with chromedp.
I tried 3.19 first. Same failure. So I switched to chromedp/headless-shell, added tini and the Noto fonts on top, and it worked first try. The image is about 280MB — comparable to Alpine + Chromium — and it's a known-good combination tested by the chromedp maintainers.
I documented the decision in the Dockerfile:
### Why chromedp/headless-shell instead of alpine + chromium:
#
Alpine 3.20's chromium 131 packaging is broken — chrome_crashpad_handler is launched unconditionally and aborts with "--database is required" before any flag we pass is honoured. Alpine 3.19 (chromium 121) shows the same failure. The chromedp/headless-shell image ships a curated headless chromium that's known-good with chromedp and is what the upstream project recommends for production.Comments are usually a code smell, but a comment explaining a non-obvious dependency choice — especially a "we tried the obvious thing and it doesn't work" — is exactly the kind of comment that belongs in code. The next person who tries to slim the image by switching to Alpine will hit the same wall I did, three months from now, with less context.
Validating the fix
The point of v2 was to stop hanging. Three independent fixes each plausibly help, but I wanted evidence. So the soak test is the regression gate:
- 1000 sequential requests
- Then 50-wide parallel waves for 10 minutes
- At the end, assert:
/readyzstill returns 200 (browser process still healthy)- RSS within 100MB of baseline (no leak)
- Zero zombie processes inside the container — this is the v1 hang's signature
/v1/stats.totals.requestsmatches what we sent
I ran a compressed version against the built image. 101 requests, 0 failures, 0 zombies, RSS flat. Then I ran the full version, twice. Same result.
The thing I want to remember about soak tests is that the failure mode you're guarding against often doesn't manifest at low volume. v1's hang showed up after tens of thousands of requests over weeks. Reproducing it deterministically in 10 minutes required pushing process creation rates well above production. If I'd only tested correctness at low volume, all three of my new bugs would have shipped and I'd have rediscovered them in production.
What I'd do differently next time
A few notes for future-me:
-
Read the package source, not just the docs. The chromedp parent-context lifetime behavior is exactly the kind of thing docs gloss over and source code makes obvious. I lost an hour to assumptions; the source took five minutes.
-
Listener-then-trigger is a strong default. Whenever I'm wiring an event listener, I now ask: "Could the event fire before the listener attaches?" If the answer is anything other than no, the listener goes first.
-
tiniis free; use it always. Anyone reading a Dockerfile in 2026 and seeing the application binary as PID 1 should reach fortini. There's no downside, the image cost is tiny, and the failure mode without it is invisible for weeks before it kills you. -
Don't trust a base image without exercising it. I would have caught the Alpine/crashpad bug on day one if I'd done a smoke test of
chromium-browser --headless about:blankinside the chosen image before writing any application code. -
Comment the "why this dependency" decisions. Code quality folklore says don't write comments — and that's right for "what this does" comments. But "we tried X and it doesn't work because Y" is institutional knowledge that lives in your head until you write it down.
Where DocPipe is now
v2 has been running in production for a few weeks. The dashboard shows ~3 requests/second average with peaks near 40/s during exam events, p95 latency around 800ms, zero browser restarts after the first day, and the analytics file on disk is roughly the size of a screenshot.
The legacy v1 endpoint still works — POST /api/html-to-pdf accepts the old payload, returns admit_card.pdf, and emits Deprecation: true + Sunset headers so the portal team knows to migrate. When they do, that handler comes out and v3 stops being a thing I have to think about.
The image lives at ghcr.io/monzim/docpipe. The source is at github.com/monzim/docpipe. The complete writeup with architecture diagrams and the full request lifecycle is in the repo's ARCHITECTURE.md.
You can check the deployed dashboard from here https://docpipe.services.monzim.com/v1/stats/dashboard
If you're building anything similar — synchronous, browser-backed, supposed to stay up forever — read internal/render/browser.go first. The fixes there are the load-bearing ones.