
Status: Resolved · DocPipe v2 (2026-05) supersedes v1. Severity: Sev-2 — service unavailable until manual container restart. Format: Blameless postmortem, modelled on Google SRE Chapter 15.
Summary
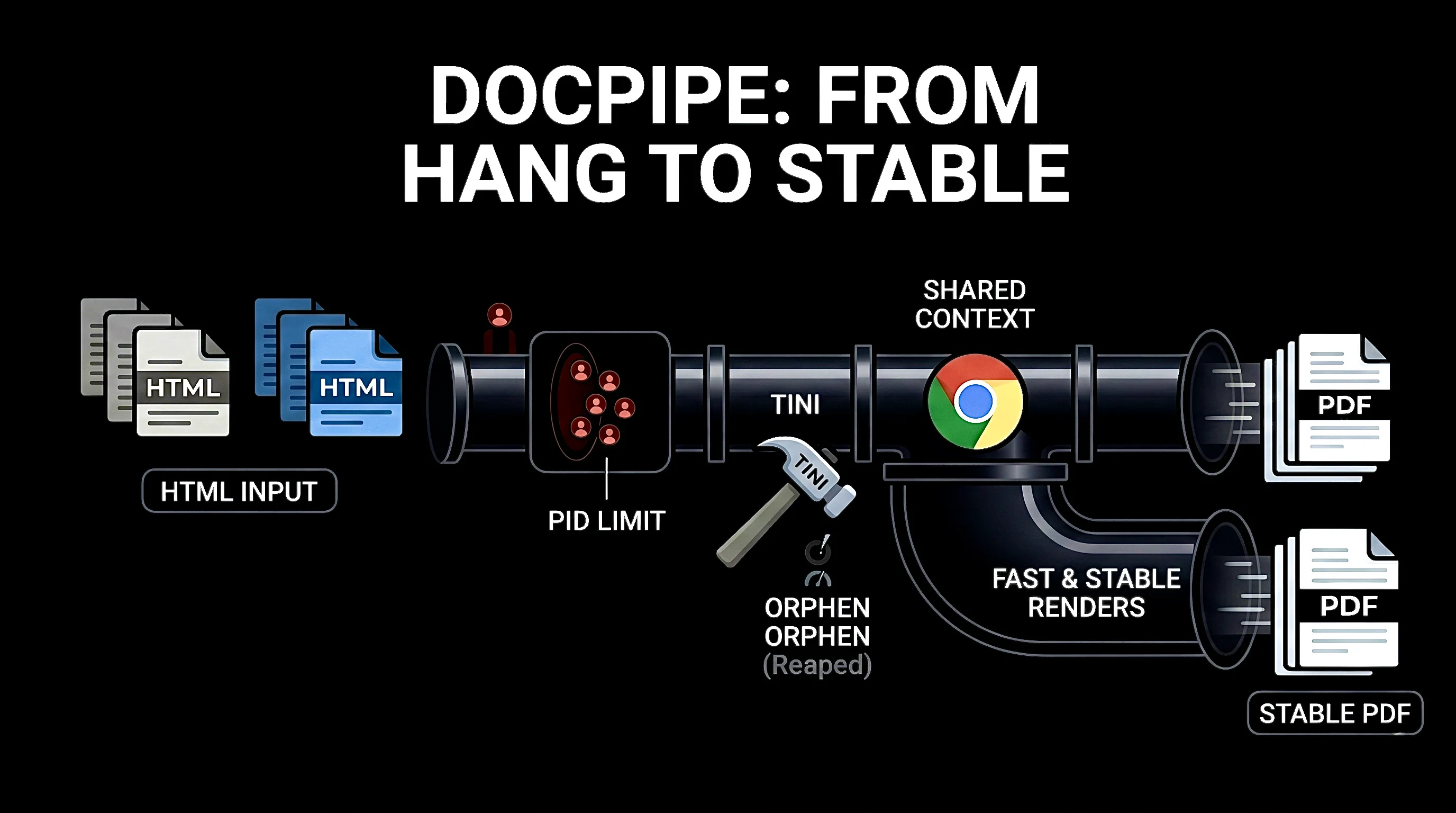
DocPipe v1 — a single-binary HTML-to-PDF service — hung intermittently under sustained load. The hang manifested as healthy /healthz responses while the conversion endpoint stopped completing requests. Recovery required a manual container restart. The root cause was a combination of orphaned Chromium grandchildren (no PID-1 reaper) and per-request Chromium spawns that leaked file descriptors over time. DocPipe v2 replaces the spawn model with one long-lived Chromium process plus tini as PID 1; a soak test now gates every release.
Impact
- Duration: Recurrent over the last 6 weeks of v1's life. Each episode lasted 5–25 minutes before manual intervention.
- Surface: The CASCK job portal —
POST /api/html-to-pdfreturns hung — which downstream blocked admit-card generation during recruitment windows. - Users affected: Estimated low-thousands per incident window, all routed through the same internal portal.
- Data loss: None. Requests timed out cleanly on the client side; no partial PDFs persisted.
Timeline
All times approximate, local (UTC+6).
- T-0 (steady state): Service serving 5–20 RPS, p95 800 ms. No alerts.
- T+0 — first symptom: A request to
/api/html-to-pdfdoes not complete inside the client's 30 s timeout. Healthz still 200. - T+5 min: Two subsequent requests time out. On-call paged.
- T+8 min:
docker exec ... psshows ~80 zombie processes parented to the Go binary.fork()is failing. Logs showresource temporarily unavailableon Chromium spawn. - T+12 min: Container restarted. Service recovers.
- Recurrence interval: Variable — once per ~24 h under sustained load; faster under bursts.
Root causes
Three problems compounded:
-
No PID-1 reaper. The Go binary ran as PID 1 in the container and did not reap orphaned grandchildren.
chromedpspawns Chromium as a child; Chromium spawns helper processes (renderer, GPU, utility) as grandchildren. When the parent Chromium exits abnormally, those grandchildren are reparented to PID 1, which never callswait()— they accumulate as zombies. Eventuallyfork()returnsEAGAINand new conversions cannot start. -
Per-request Chromium spawn. Every conversion launched a fresh
chromedp.NewContext(...)rooted at a newexec.Command. Under steady load this multiplied (1) by request rate. -
Hang masquerading as healthy.
/healthzwas a static200 OK. It did not probe the browser, so the service reported healthy while the hot path was deadlocked behind a failingfork().
Trigger
The combination existed from day one. It only manifested past a request-rate threshold (~8 RPS sustained for ~20 minutes) where zombie accumulation outpaced the rare cases of Chromium clean shutdown.
Resolution (DocPipe v2)
-
Replaced per-request spawn with one long-lived Chromium process plus a supervisor goroutine that probes the browser every 30 s and recycles it on failure or after a configurable render count. Per-request tabs are now derived from a shared parent context. A semaphore caps concurrent tabs so a slow renderer cannot starve others.
-
Added
tinias PID 1. Application binaries make poor PID 1s.tinicosts nothing, lives in a couple of KB, and reaps grandchildren correctly. -
/readyznow reflects actual browser health. A failing browser produces a non-200 readyz so the orchestrator pulls the pod out of rotation rather than continuing to send requests to a deadlocked instance. -
Soak test as a release gate. Every release runs 1000 sequential conversions plus 50-wide parallel waves for 10 minutes, asserting zero zombie processes inside the container, RSS within 100 MB of baseline, and analytics totals matching what was sent. The v1 hang doesn't manifest at low volume, so unit tests alone could not have caught it. The soak proves the fix at production scale before every deploy.
Detection
What we had:
- A static health endpoint that always passed.
- Client-side timeout alerts (which is how we found out).
What we have now:
/readyzprobes the actual browser process.- Analytics expose per-status-code counts + p95/p99 latency. A latency spike or sudden absence of
200s alerts oncall via the existing dashboard. - The soak test runs in CI on every release. A regression of the underlying class of bug fails the build, not production.
Lessons learned
- Health checks must probe what matters. A
200 OKstatic handler is worse than no health check — it masks the failure mode and breaks orchestrator self-healing. - PID 1 is a real concern even in small containers. If a process can become PID 1, decide explicitly who reaps zombies.
tiniis the right answer for almost every application image. - Spawn-per-request is a smell when the spawned process is heavyweight. Chromium falls in that bucket. A bounded pool gives predictable memory + FD usage and removes a whole class of orchestration bug.
- Soak tests beat unit tests for time-and-resource-correlated failures. Run the same workload-shape for long enough at production-ish concurrency, then assert the invariants (zero zombies, bounded RSS, totals match).
Action items
- ✅ Replace spawn model with long-lived Chromium pool (
DocPipe v2). - ✅ Add
tinias PID 1 to the container image. - ✅
/readyzreflects browser health. - ✅ Soak test as release gate.
- ✅ Public stats dashboard exposes p95/p99 and rolling 1 h / 24 h windows.
- ☐ Weighted-fair queueing over the semaphore — noisy callers can hold slots up to the timeout and starve neighbours. Out of v2 scope; tracked.
- ☐ T-digest behind the existing
Observe(int64)interface, swappable when the fixed-bucket histograms stop being good enough.